
AIDD
Description for AIDD
Multimodal Artificial Intelligence Large Models for Small-Molecule Drug Generation and Description
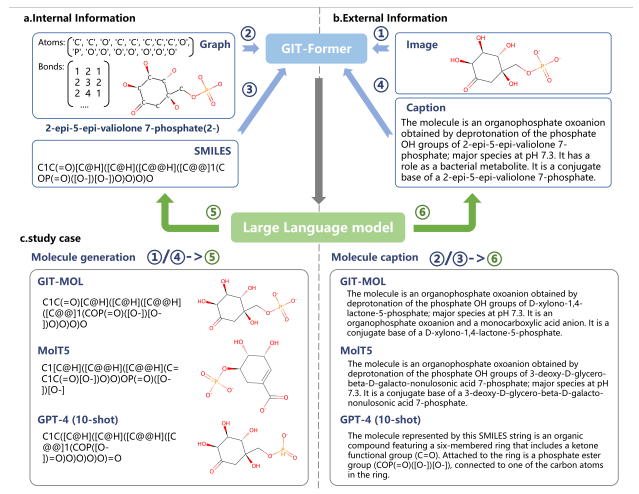
We are dedicated to the development of an innovative multimodal large model in the fields of drug discovery and molecular biology, aiming to provide new perspectives and solutions for understanding and utilizing multimodal molecular data. To this end, we have designed and implemented a multimodal AI large model capable of simultaneously processing images, graphs, and text. Through a novel cross-modal fusion approach (identifying and extracting correlations between different modalities and implementing cross-fusion of information, thereby generating a unified embedding that integrates multimodal information), our model achieves an organic interaction and efficient fusion among these three modalities. Our model has demonstrated outstanding performance across various small-molecule drug tasks, with the ability to understand and handle multimodal molecular data. It has accomplished accurate prediction of molecular properties, as well as the generation and description of molecules in response to textual prompts, showing superior performance in comparison with models of similar levels.
Deep Neural Network-Based Research on Small-Molecule Drugs

By designing novel molecular representation methods and utilizing the force field computations and knowledge-base optimization features of RDKit, we generate 3D conformations of molecules from molecular topological graphs. Subsequently, we decompose the molecular conformations into point-edge graphs, bond-angle graphs, and dihedral-angle graphs to comprehensively characterize the spatial information of molecules and extract the 3D structure of small-molecule drugs. We have designed a molecular encoder based on a message-passing model and pre-trained their model using extensive unlabeled small-molecule data through a self-supervised contrastive learning approach (using molecular topological graphs). Our AI model has achieved state-of-the-art (SOTA) performance in several aspects of small-molecule drug property prediction.
Bioinformation
Description for Bioinformation
Large-Scale Natural Ingredient Database and Intelligent Bioactivity Analysis

We have constructed a natural product data platform that integrates both traditional Chinese medicine (TCM) and Western medicine information, aiming to realize the modernization of TCM and provide in-depth support for precision diagnosis, treatment, and drug development. This platform integrates the core concepts of TCM and modern medicine by fusing 49 kinds of entity relationships, including traditional medicinal materials, TCM symptoms, prescriptions, and modern medicine entities such as molecules, targets, pathways, and drug side effects. This integration has led to the creation of a TCM modernization knowledge graph containing over 5 million triplets. To support knowledge discovery within the platform, we employed a pre-trained heterogeneous graph model to handle this complex data, utilizing advanced AI technologies for deep mining, and implementing various pharmaceutical services such as drug repositioning, side effect prediction, drug target prediction, and dosage prescription generation. Furthermore, we have constructed an online platform to intuitively display the data and enable online prescription generation. This method not only effectively interprets the knowledge of natural products in both Chinese and Western medicine but also exhibits high consistency with real experimental results, providing robust support for the modernization of TCM, new drug discovery, and personalized treatment. Additionally, we have collected 378 TCM prescriptions for enteritis and employed a novel and effective data augmentation strategy to expand the training dataset. We have utilized a deep neural network comprising 9,845 nodes and 161,950 edges, incorporating microscopic information through feature embedding, including bioactive molecules, protein targets, and prescription extraction features. Subsequent network pharmacology validation revealed that the ten most common ingredients in the AI-generated prescriptions were related to various inflammatory signaling pathways. To further validate the bioactive components in the generated prescriptions, we selected five effective ingredients for wet-lab experiments on BALB/c mice with colitis and confirmed their inhibitory effects on pro-inflammatory factors. This demonstrated the reliability of our AI model in identifying bioactive components from TCM prescriptions.
Tumor Immune Microenvironment Analysis Based on Machine Learning

We have integrated single-cell RNA sequencing data from multiple public databases, filtering 695 processed tumor immune cell samples to construct a tumor immune microenvironment single-cell dataset covering 39 types of cancer (currently the largest tumor immune microenvironment dataset). To address the issue of overly generalized data visualization results, we designed a refined data processing workflow and applied a random forest model to extract unique cellular factor expression patterns for various cancer categories. This pioneering approach enabled high-precision cancer type discrimination based on the expression of immune microenvironment cellular factors. This discovery not only deepens our understanding of the type-specific immune regulation within the tumor immune microenvironment but also provides essential references for future cancer diagnosis and treatment, markedly demonstrating the tremendous potential and application value of artificial intelligence in the field of biomedical research.
Gravitational Wave Science
Description for Gravitational Wave Science
Intelligent Time-Series Scientific Data Processing
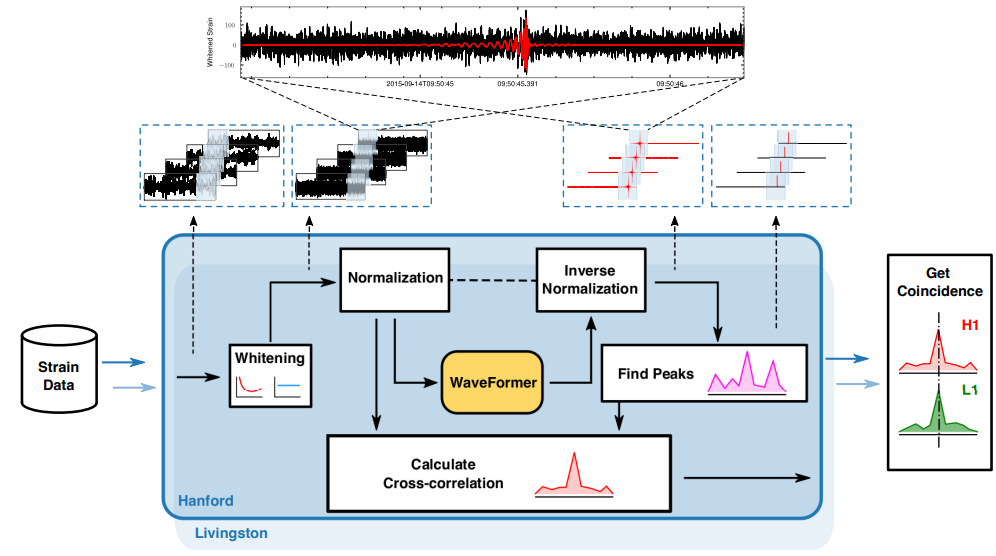
Utilizing deep learning to separate signal from noise and mine information in commonly low signal-to-noise ratio (SNR) data in scientific domains: (1) To address the computational complexity bottleneck of existing Transformer models, we propose a multi-dimensional sparse self-attention method, achieving efficient training for models with up to billions of parameters. By integrating multi-level embedding features and training with a masked objective function, this method is applied to the field of signal denoising in low SNR data, achieving the best denoising effects in the current domain. (2) To overcome the limitation of existing CNNs that cannot handle ultra-long time-series signals, we propose an architecture combining dilated convolutions and recurrent neural networks. This structure enables long-term memory in the algorithm, fully learning the features of ultra-long sequences, and its application in signal detection has substantially improved detection accuracy. (3) To address the bottleneck of lengthy computational time in traditional matched filtering and Monte Carlo sampling methods, we propose a time-series signal parameter inversion algorithm based on Normalizing Flow. This deep learning algorithm can replace traditional methods, accelerating convergence through a massive number of trainable parameters. Leveraging the powerful computing capabilities of intelligent computing clusters and applying them to the field of signal parameter inversion, this method simultaneously enhances the speed and accuracy of signal parameter inversion. (4) In response to the current scarcity of open-source time-series datasets in the scientific field, we have constructed an open-source database platform and provided various categories of time-series datasets for researchers to download. Additionally, to overcome the bottlenecks of time-consuming generation, significant storage space occupation, and time-consuming data loading for long-term time-series data, we propose an adaptive parallel generation method based on in-memory databases. This solution provides ample data for large model training, accelerating the training of large-scale AI models.
Intelligent Computing Publication
Description for Intelligent Computing Publication
Performance Evaluation and Application Platform for Large-Scale Intelligent Computing Systems
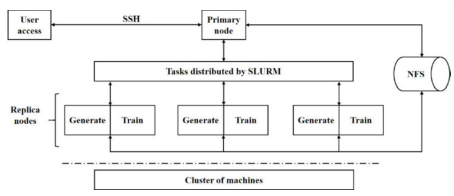
Performance evaluation was conducted on a large-scale intelligent computing system (consisting of 512 nodes, 4096 NPUs, 16E OPS theoretical AI computing power). By improving parameter initialization, hyperparameter optimization algorithms, and computational parallel strategies, issues such as AI accelerator idling, time-consuming model generation, and slow convergence were resolved. By developing automated deployment tools and fault tolerance mechanisms suitable for domestic intelligent computing clusters, high-speed data auto-copying required for large-scale testing was achieved. Optimization of communication strategies between large-scale nodes enabled low-latency and low-blocking task distribution among clusters. The achievements were recognized with consecutive championships for multiple years on the international AI performance AIPerf500 ranking (jointly released by ACM’s Special Interest Group on High Performance Computing in China (SIGHPC China) and China’s Big Data and Intelligent Computing Industry Alliance). Additionally, innovative research was carried out on algorithm study, model training, software optimization, etc., revolving around the design of the new generation of large-scale intelligent computing systems: (1) In the field of high-throughput data generation and processing, an in-memory database method was proposed, enabling storage-limit-breaking multi-threaded parallel data generation. (2) For large AI model training, innovative distributed training architectures were introduced, such as heuristic-guided asynchronous historical optimization algorithms, hybrid operator parallelism with decentralized communication topology for network load balancing, and model-parallel strategies for various model architectures like convolutional layer parallel splitting based on matrix outer product separation, and scalable attention mechanism parallel methods. (3) On the parallel algorithm level, improvements were made to parallel strategies targeting classic deep neural network structures, reducing communication overhead, enhancing training efficiency for large AI models, and improving model performance and convergence speed. (4) In high-performance software implementation, traditional distributed frameworks were revised, optimizing inter-node communication mechanisms to ensure training efficiency under high network latency, and enhancing the scheduling strategy of heterogeneous resources within the cluster. Surrounding the intelligent computing systems, several patents were applied for and authorized, and a large-scale intelligent computing system’s intelligent scientific research platform was constructed. The platform was optimized for stability, scalability, and compatibility, and performance improvements were made in areas such as algorithm software parallel patterns and adaptation to domestic intelligent computing systems.
Intelligent Computing Evaluation Standards and Standardization of Artificial Intelligence Computing Centers
A systematic assessment was conducted on the artificial intelligence computing center’s system architecture, performance and reliability requirements, testing methods, and more. A benchmark evaluation framework was developed for end-to-end intelligent computing that is oriented towards multimedia tasks, based on adaptive automated machine learning technology: (1) Innovatively implemented a gradual search algorithm for network structures based on convolutional blocks, utilizing a “master-slave node structure.” Slave nodes asynchronously carry out model generation and training, employing the CPU of the slave nodes to parallelly create new architectural designs, thereby enhancing the algorithm’s stability during automatic test load generation. (2) Through automated feature engineering algorithms, candidate features were autonomously created from the dataset. Several optimal values were selected from these features as expert knowledge for hyperparameter optimization, thereby enhancing the convergence speed and performance of generated loads. (3) Quantitative comparisons were realized among different hyperparameter optimization algorithms (such as random search, evolutionary algorithms), and a search for global optimum values was carried out by optimizing Bayesian methods. (4) Efficiency was achieved in the distribution of large-scale node tasks based on Kubernetes and SLURM through data parallelism and synchronous all-reduce strategies, along with the adaptive scaling of loads across machines of varying sizes. (5) An innovative application of analytical methods was used to compute floating-point operation quantities, enabling rapid and accurate predictions of the floating-point computations required in AI tasks. Additionally, the convergence of normalized scores as an evaluation metric was verified. Through a combination of the above theoretical innovations and engineering optimizations, challenges were addressed concerning hardware utilization analysis for benchmark workloads, setting costs and computation models, adaptive scalability of benchmark testing workloads, and unified performance indicators to measure AI applications. Following multiple rounds of domestic and international peer review (involving Google, Microsoft, Amazon, Tsinghua University, Peking University, Baidu, Alibaba, Tencent, Cambricon, etc.), 2 industry standards for AI computing centers were issued by the Zhongguancun Audio-Visual Industry Technology Innovation Alliance (AITISA) (T/AI 118.1—2022, T/AI 118.2—2022); an international standard for AI computing power evaluation was released by the International Telecommunication Union’s Telecommunication Standardization Sector (ITU-T SG16) (Metric and evaluation methods for AI-enabled multimedia application computing power benchmark, ITU-T F.748.18).